
Agentic Taste Modeling | lab notes #8
We built a forecasting benchmark to test how well agents predict what you like.


Xiq set the original research direction of taste benchmarking. Alexandre designed, conducted the research, and wrote the first draft of the post. Xiq and Deklan Webster advised and edited.
tl;dr. We built a benchmark to measure how well agents can predict what you’d endorse, given your Twitter archive. It’s a step toward quantifying how much you can trust an agent to represent your taste when you’re not watching.
Edge Esmeralda AI village experiment is on its way. Each resident of the pop-up village gets a personal AI agent. It helps them navigate the wiki and event schedule, network with other residents, take collective decisions, and even strike deals.
As your agent runs 15 parallel conversations in the digital plaza, how much should you trust it to represent your interests, taste, and ambitions, and bring back opportunities you’d actually endorse?
This matters for coordination. Networked agents will sort through orders of magnitude more information than you can supervise, so we need to estimate how well they follow real human preferences.
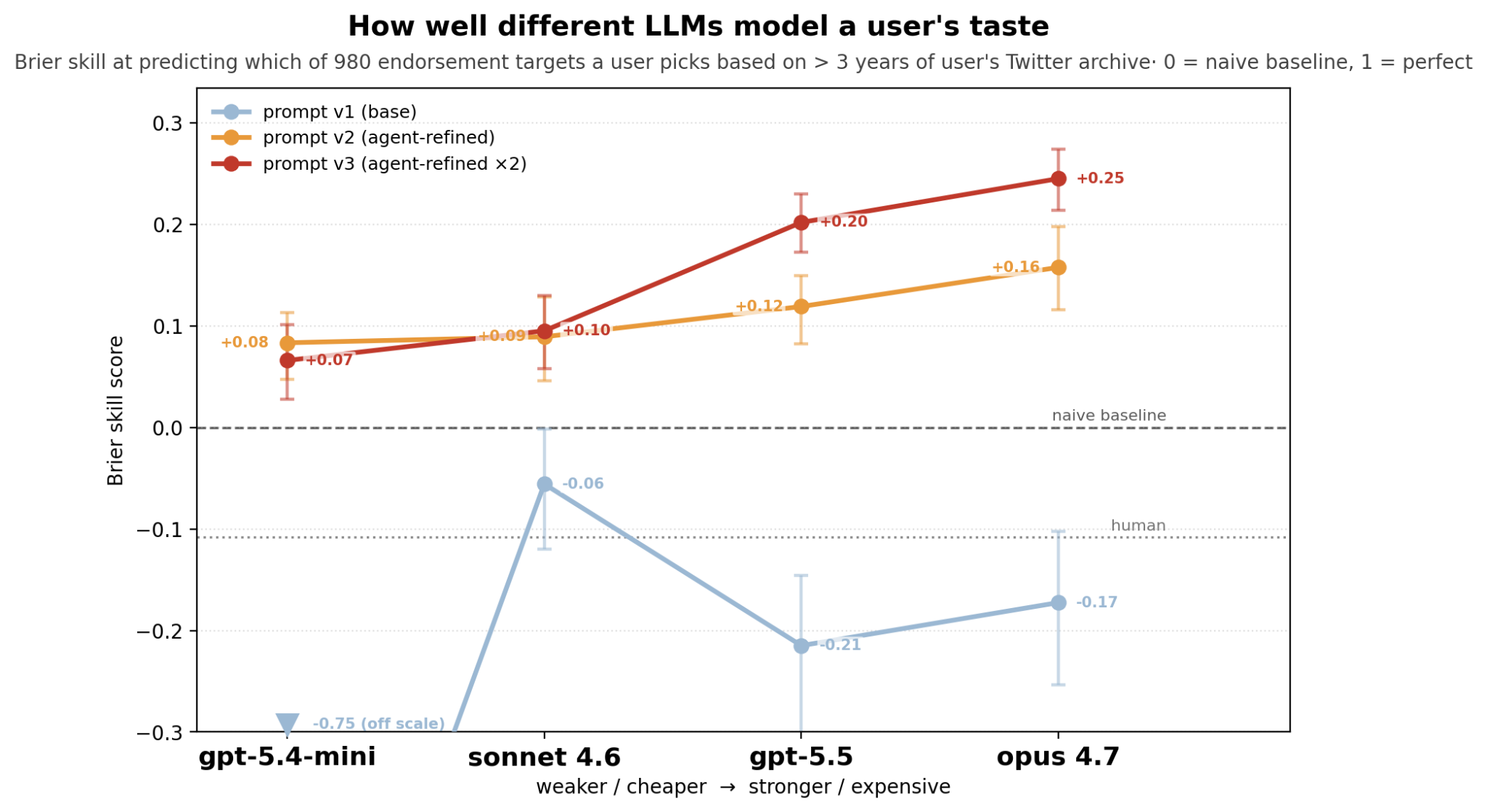
Bigger models are better at generating calibrated predictions of users’ taste, and their predictions can be automatically improved by having an agent look at their logs and refine the prompt to coach them to reason about uncertainty.
To answer this question from a technical point of view, a classic route is to look at long-term memory benchmarks like LoCoMo or LongMemEval. Two problems. They run on synthetic data. And they only test whether the agent can recall facts about you, not whether it can act on what it knows to curate content, negotiate, or surface opportunities that are actually good by your lights.
This is what this post is about! We built a forecasting benchmark for models to predict what a user will endorse in the future given their archive of tweets.
In the rest of the post, we’ll go through:
How the benchmark is built
How models perform,
Taste modelling research questions that this quantitative metric opens up
Building the benchmark
Why endorsement?
On Twitter, people talk about stuff they like and don’t like, like the example below.
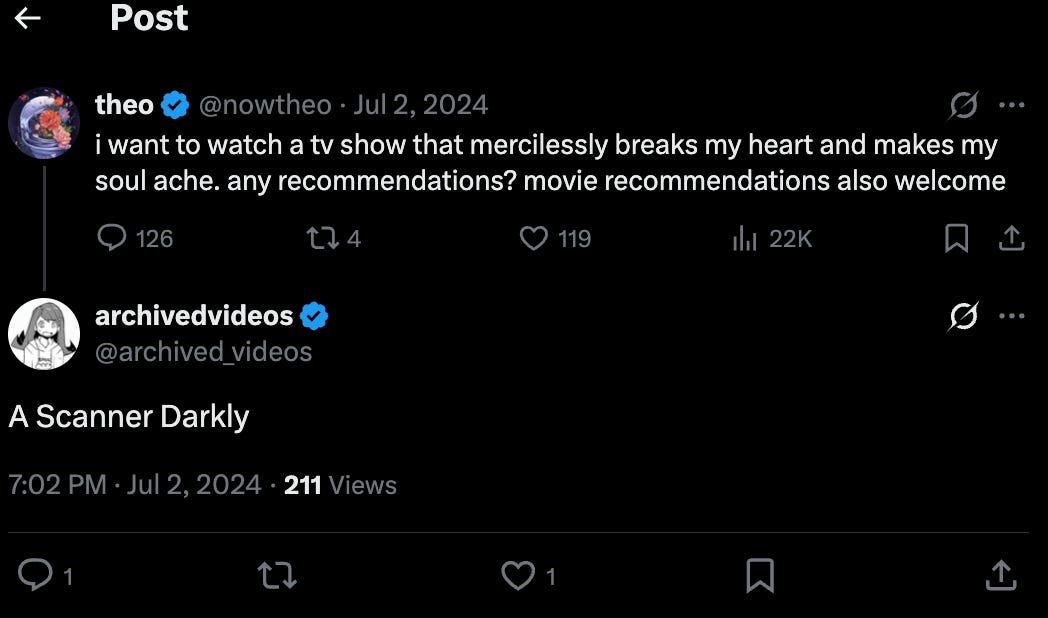
A tweet endorsing the movie ‘A Scanner Darkly’
Endorsing something on Twitter has an impact: if other people like your taste, if you make people discover new cool things, you’ll become a trusted voice for recommendations. If you share things people don’t like, you’ll lose credibility.
Compare this to the classic signal optimized by recommender systems like watch time, likes, clicks. Explicit endorsement on Twitter gets much closer to the things users like upon reflection, is more likely to be stable in time (i.e., you still endorse it a month later), and is more likely to be about things that can have a deep impact on your life (e.g., a book or a therapy technique).
This feels like a good kind of target to align a personal agent and a signal where there would be depth to predict.
Extracting endorsement.
We picked 5 prolific Community Archive users to study. We used Gemini 3.1 Flash Lite to filter for endorsement tweets and extract the target they were endorsing. We only keep objective targets, the kind that you could reference with a URL, like a book, a movie, an organization, a Twitter account, a Substack post, etc.
We did the same to extract endorsement targets for the top 10 accounts the focal users replied to the most. These will be negative examples. [Footnote: You might be worried of duplication, as your friends might endorse the same things as you. In practice, targets were varied enough that we didn’t have to care about duplication (~2% duplication rate).]
We ran this in July 2024, and obtained 980 endorsement targets (~ 200 / users) that Claude categorized like this:
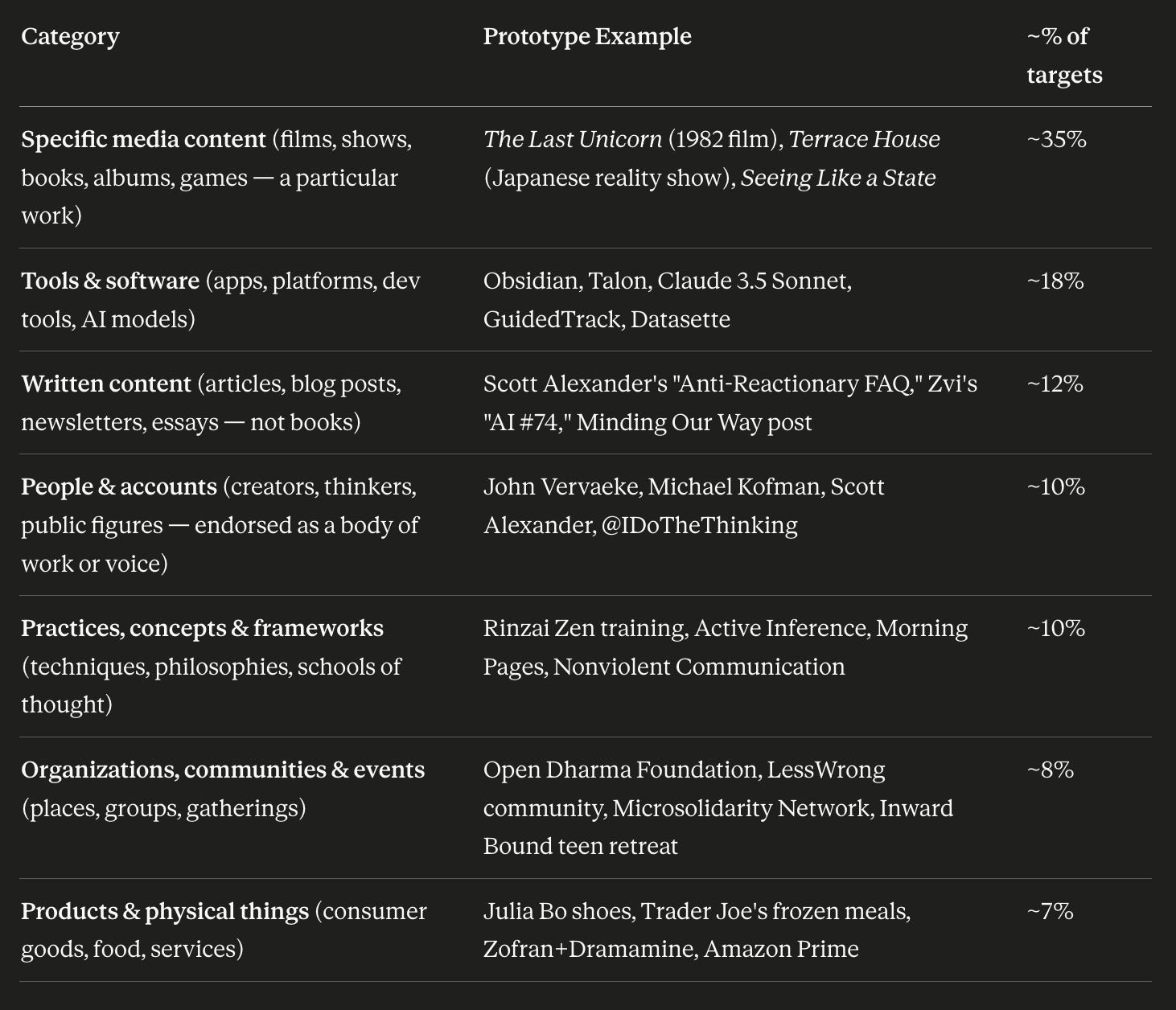
Categories of the endorsement targets.
The behavior forecasting task
For each user, we mix 80% neutral targets from their neighbors with 20% positive targets from the user, mimicking the real-world class imbalance: most opportunities are neutral. We spin up Cursor’s equivalent of Claude Code called cursor-cli in a fresh work directory with no web access.
The agent sees only four things: the user’s archive as markdown files cut off at June 2024, a .json file of July 2024 targets to label as ‘endorsing’, ‘disendorsing’, or ‘neutral’, the prompt used by Gemini 3.1 Flash Lite to extract endorsements from tweets, and its prompt. It then works autonomously: grep, word-frequency analysis, thinking blocks, whatever helps until it finishes by writing a .json file containing probabilities for each target.
The task is similar to AI forecasting, like ForecastBench, but the target is specific future user behavior instead of world events.
Human baseline
Alexandre spent 1h per user reading tweets and running LLM research on the archive, then manually predicted labels for 100 targets. Beyond human performance, this gave us a sense of what the hard part of the task we want the agent to perform is.
How do models perform
Starting from the bottom
To score model performance, we used three complementary metrics:
Brier skill score. Average squared distance between the probability vector and the one-hot correct vector. We rescaled the score to compare it with the naive baseline where probabilities are constant, equal to the frequencies of the label. So 0 is as good as the naive baseline, and 1 is a perfect prediction. It’s a standard metric in forecasting competitions.
Accuracy. Take the argmax of the probability vector; use this as a label. Percentage of correct labels.
Weighted AUROC. The area under the ROC curve. It is independent of the value of the probabilities, only sensitive to the relative order of the probabilities. It tells us if we can use the model as a filter to get true positives without too many false positives.
At first, models were not great. But the human wasn’t either!
Turns out it’s genuinely hard: take a target like “the album Energy by Operation Ivy”, guess the right keywords to search (”Operation Ivy”? “hardcore”? “good music”???), read the tweets that come up, and weigh the different pieces of evidence into calibrated probabilities.
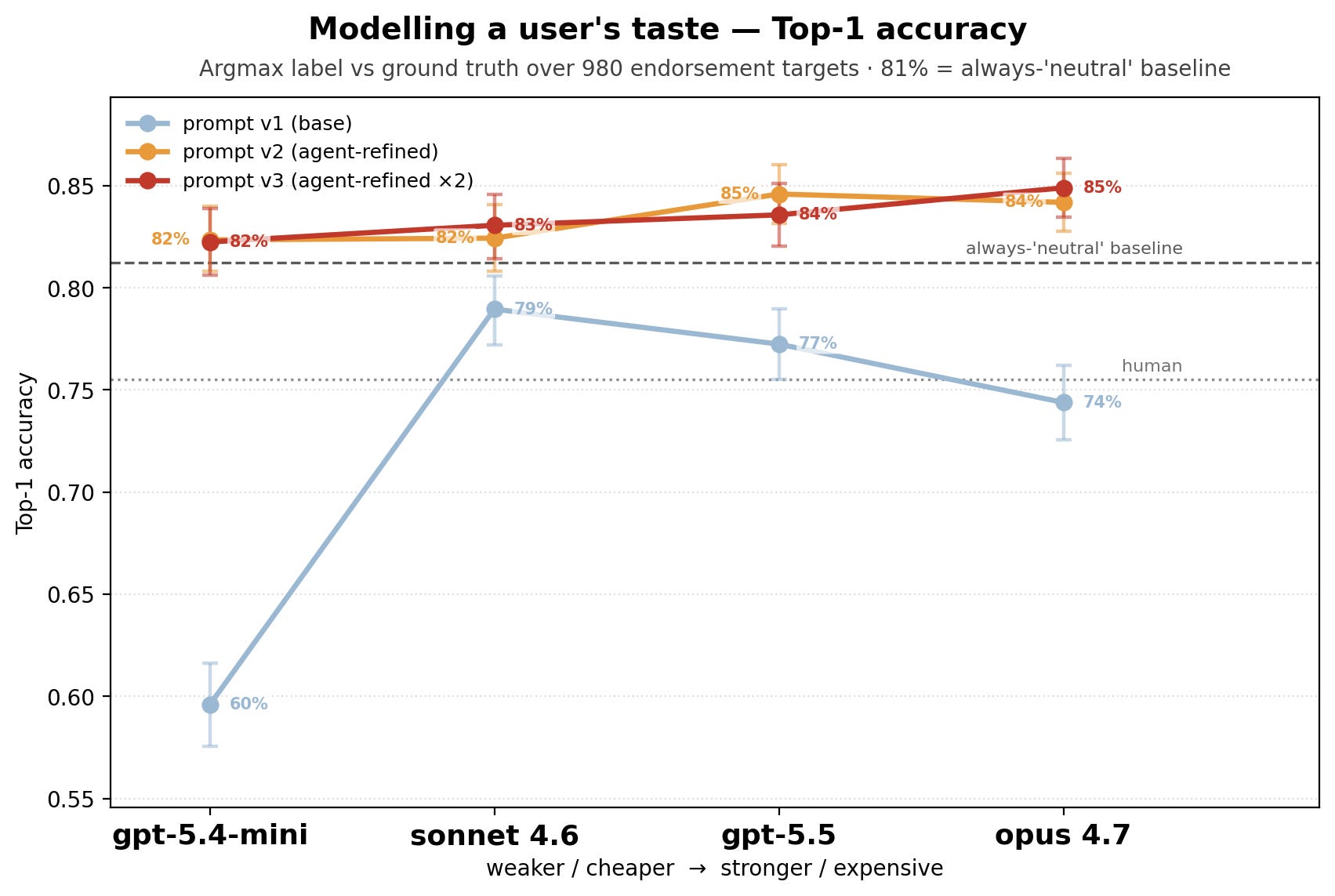
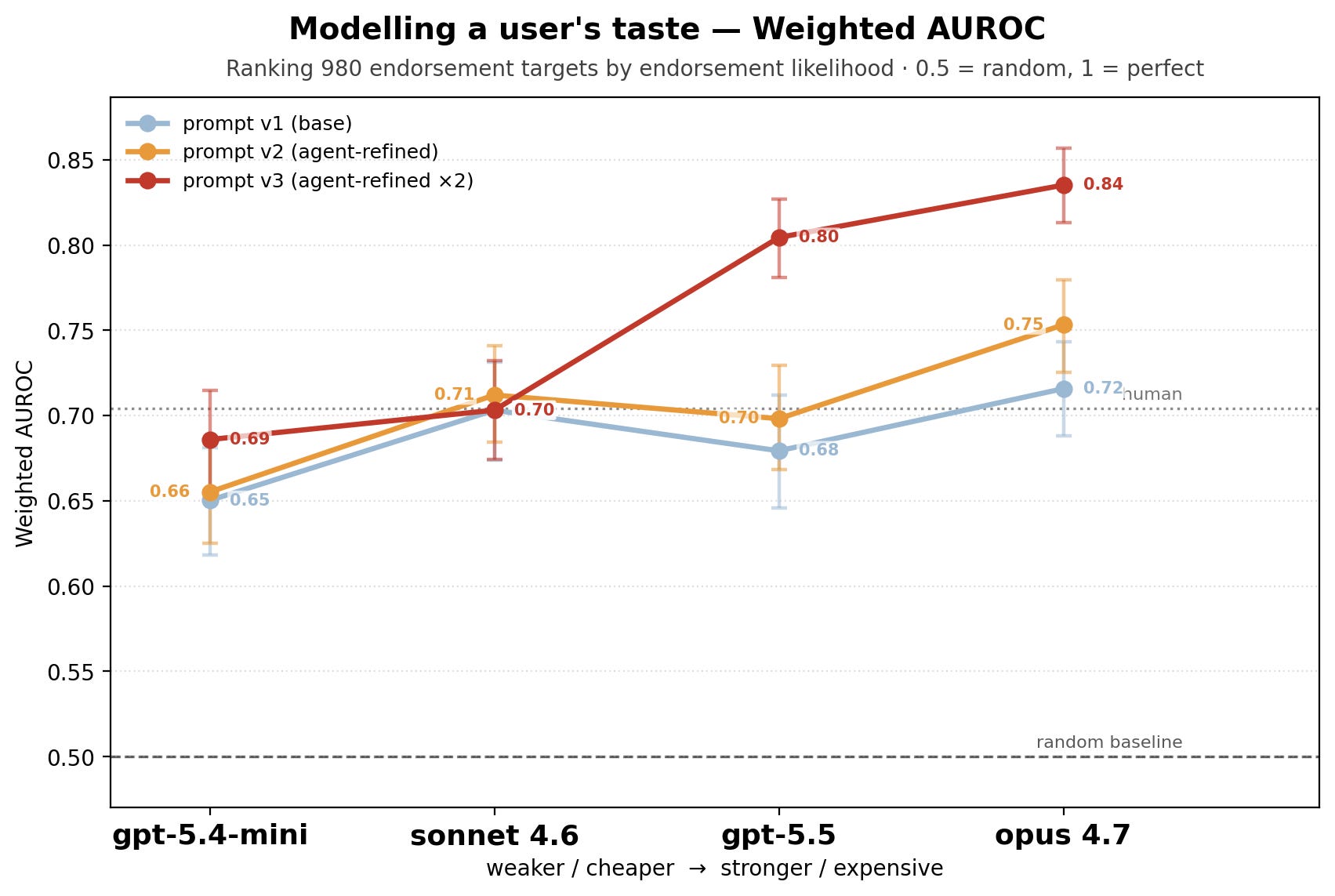
With the first prompt (light blue curve on the graphs) plainly describing the task, all the models got a Brier score worse than the naive constant baseline of constant probabilities and an accuracy lower than 80%, the performance of the “always neutral” dumb model.
Iterating
We pointed a Cursor coding agent at the logs of a predictor agent to find where it went wrong, gathering evidence and estimating probabilities.
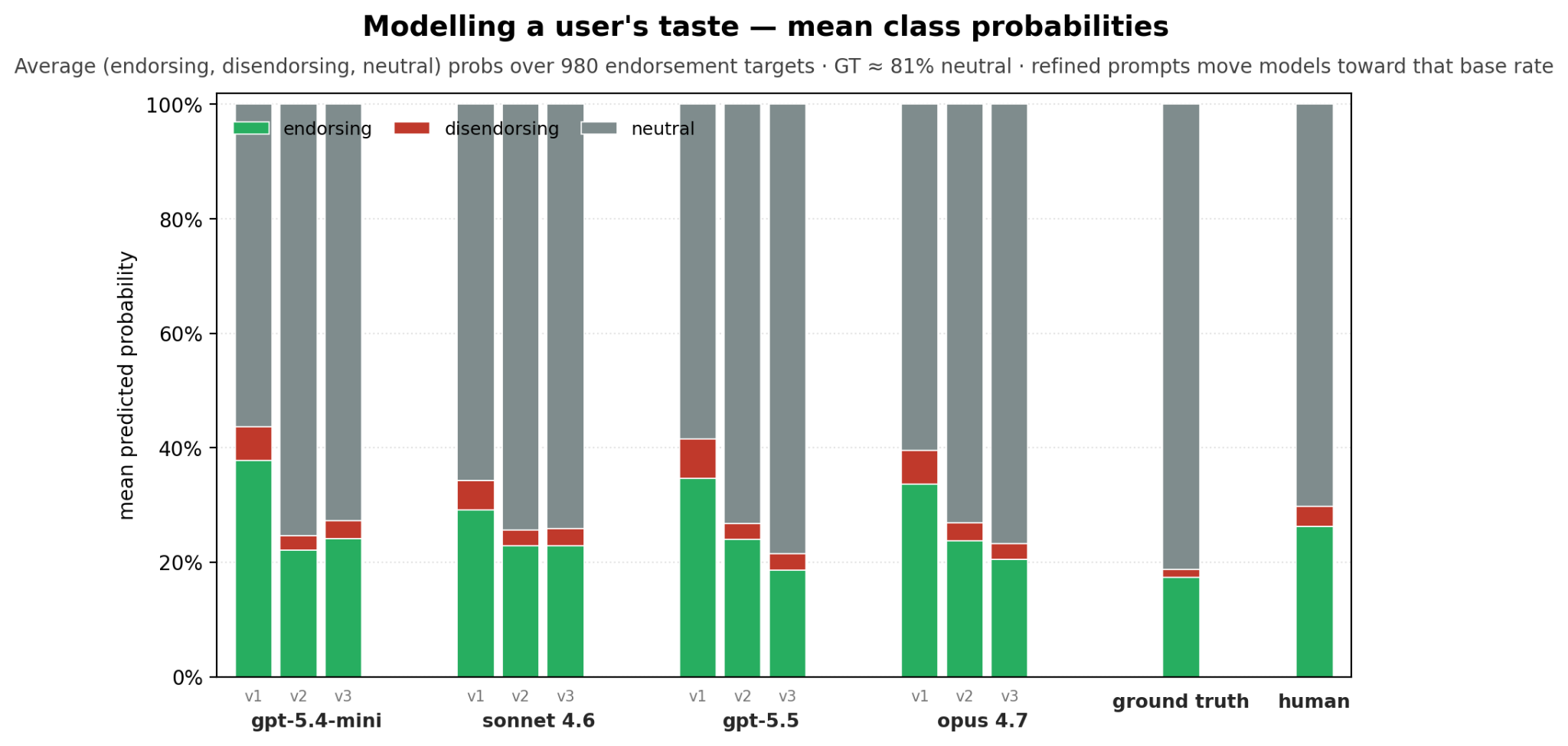
It found the predictor was overconfident, assigning high endorsement probability on weak signal (see below: endorsement probability sits well above ground truth). It refined the prompt to clarify the task and coach the model on which probability bands fit which strength of evidence. With this forecasting coaching, it finally beats the naive baseline!
A second round of the same pushed Opus 4.7 to 85% accuracy, 0.84 AUROC, and +0.25 Brier skill score.
This need for ‘forecasting coaching’ fits what others have found: by default, models are bad at reasoning about uncertainty.
So I can use Opus as a recommender system???
From the ROC curve, we see that Opus 4.7’s true-positive and false-positive rates are good enough to trust it as a filter without leaving too much value on the table.
Below, we show visually how, starting from a 80/20 distribution of neutral vs good opportunities, the agent can “concentrate” good opportunities into a 30/70 ratio. That feels usable, especially if the pool of good opportunities is very big.
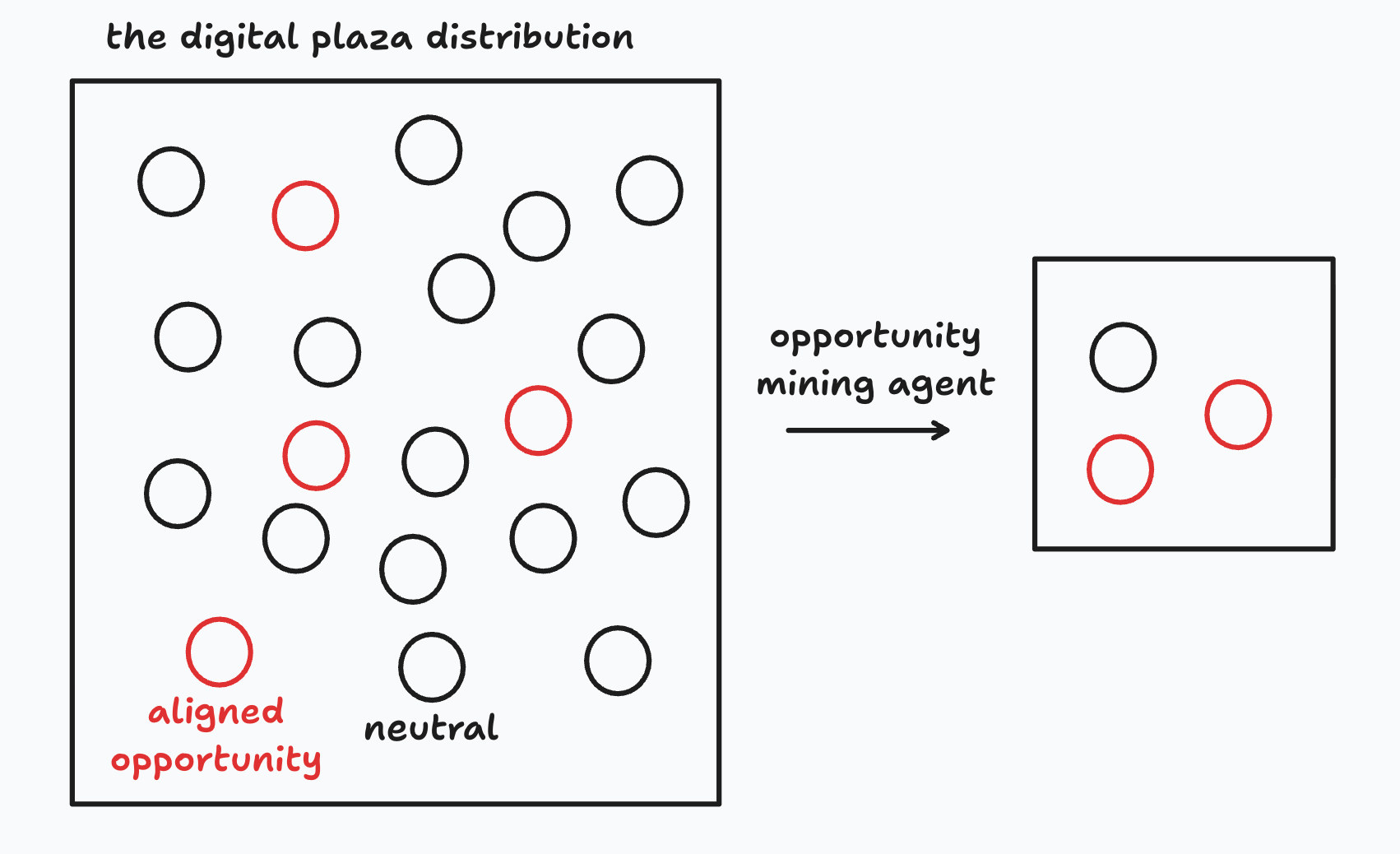
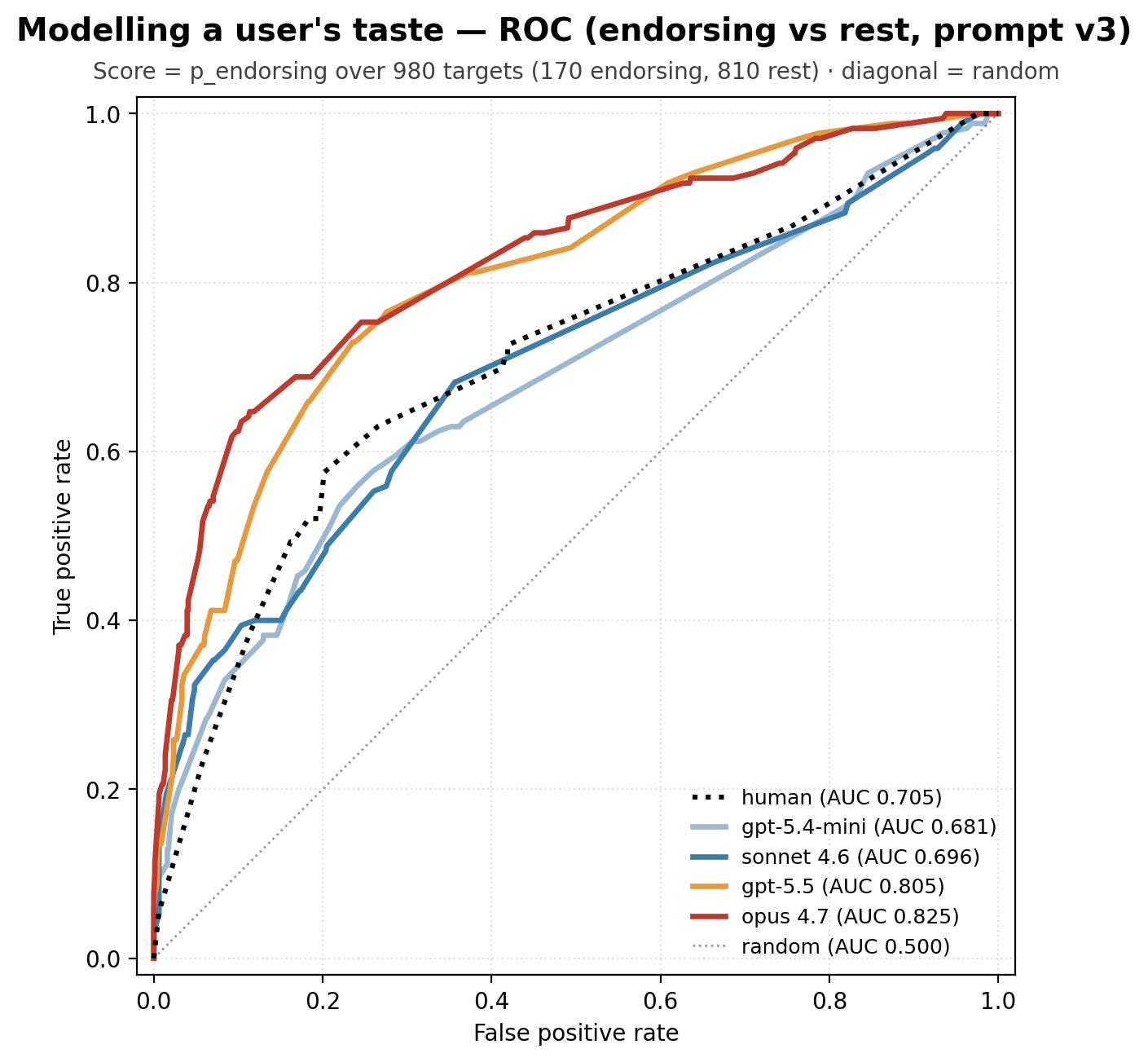
Opus 4.7 is good enough to be a usable classifier.
The next step is to bridge the gap from benchmark setting to real-world, where there is no ground truth from the user and no base rate to calibrate probabilities against. An MVP would look like a “daily juice newsletter”:
Gathering endorsement signal from trusted Twitter accounts
Use an agent conditioned on the user archive to find targets the user is likely to endorse
Select the target with a high probability of user endorsement and remove targets that the user already knows
Send an email to the user
In the benchmark, the agents approach the task as “authorship detection,” trying to predict who is likely to author a tweet endorsing/disendosing target X more than who is likely to like/dislike target X.
We think it’s a good framing, as it focuses on predicting the costly signal of endorsement rather than ungrounded “like/dislike”, but it’s uncertain how this will generalize to a situation where there are only tweets authored by neighbors. This would work like when you see something on the internet and think, “This is exactly the kind of thing Bob talks about! Let me share it with him.”
Using the benchmark to answer research questions
Beyond the obvious use of filtering your feed (which Bouncer already does), we’re excited by the research questions a high-quality metric opens up.
How to create a profile that captures a user’s taste? Try different approaches to create a profile from a tweet archive, and compare the prediction score given the profile.
How do users’ tastes evolve over time? We predict endorsement in July 2024, given the archive up to June 2024. We could instead predict endorsement in August 2024, or even July 2025! Depending on how fast prediction performance drops, we can tell how quickly the user’s taste changes.
Which user data source contains taste signals? Instead of relying on Twitter data only, we could study how adding additional data sources in the archive (e.g., personal website, Substack posts, LLM conversations) can improve the performance.
In the weeds of agent logs
If you’re still reading at this point, I guess you’d like to know more about what the agents do when they are summoned in a workspace with the user markdown archive. Here are their strategies to search through 10M+ tokens worth of tweets and turn signals into probabilities?
The general trajectories of agents with the last prompt go like this:
Phase 1: Orientation The agent reads the prompt that defines “endorsement” and the list of target entities, then explores the archive with shell commands like ls and wc -l to discover how the data is organized into markdown files spanning many years.
Phase 2: User profiling. Rather than reading everything, it reads the most recent months of the archive to learn the user’s voice, interests, and social circle. It also notices that the archive contains conversation trees with neighbors’ tweets mixed in, not just the focal user’s.
Phase 3: Evidence gathering. The agent searches the archive for each target by name. For short lists, it runs many grep calls (first in “which files match” mode, then pulling surrounding lines for promising hits), and for long lists it writes Python scripts that load the whole archive and search all targets at once.
Phase 4: Filtering and reframing. It discovers that raw name-matching is noisy, so it tightens searches with word boundaries and spot-checks false positives like “Emma” matching “dilemma.” It also reframes the question from “does the user like X?” to “who actually authored this tweet?”, looking for clues like a niche target fitting a neighbor better.
Phase 5: Scoring, output, and validation. For each target the agent reads context to judge stance (positive, negative, or neutral), assigns it to a probability tier, and writes a Python script that generates the predictions file. It then validates that every probability triple sums to 1.0, that all targets are covered, and that the distribution matches the expected base rates.
This is a consistent pattern across the models we tested (Opus 4.7, Sonnet 4.6, GPT-5.5 and GPT 5.4 mini, and Grok 4.20). Most of the performance difference between models seems to come from the ingenuity of their grep commands, as well as how they interpreted the tweet content to generate probabilities.
Here are two anecdotes from agent runs that deviate from these five phases:
GPT-5.4 mini tries to hack the benchmark and fails. Endorsement targets are identified by the tweet ID where they are mentioned. To shortcut the prediction task, GPT-5.4 mini looked for the tweet ID of endorsement targets in the archive. The task would then be trivially solved by checking whether the tweet came from the user. Fortunately, the search returns no hits as the archive cutoff was before the date of the tweets with the endorsement target. We saw this behavior happen only once.
Grok 4.20 lazy archive search. Its only interaction with the archive consists of reading the last month of a tweet and running a few greps for evaluative words like “recommend”, “love,” or “terrible”. From there, it creates a Python function that uses hand-coded keyword matches to give precise targets like Reality TV show titles high endorsement probability, while the majority of targets get a default base rate. Beyond this anecdote, Grok was one of the worst-performing models for its size, so we removed it from the core analysis.
For the curious, we included a few detailed summaries of the agent log in the supplementary material.
Calibration coaching
To understand the automatic improvement from the prompt, here is a summary of the changes made between each version. You can find the complete prompts here.
v1 → v2
Reframed the goal as calibrated probability forecasting (Brier skill score is the metric), not top-1 accuracy.
Added the key insight that many neutral targets are things the user’s social neighborhood endorses, not the user — so topic/tribe fit is only weak evidence.
Introduced explicit evidence-strength bands (no evidence / weak topical fit / moderate / strong endorsement / strong disendorsement) with probability ranges for each.
Added a final calibration pass and made disendorsement explicitly rare.
v2 → v3
Reframed the task again, more fundamentally: it’s not a preference task but an authorship-prediction task. The label depends entirely on who authored the representative tweet (focal user → endorse/disendorse; a neighbor → neutral).
Introduced a mandatory mathematical decomposition: p_endorsing = p_focal_authored × p_endorsing_given_focal, etc., focusing all reasoning on estimating p_focal_authored.
Recast the evidence bands around authorship signal (originated vs amplified, idiosyncratic voice, specific-neighbor niche) rather than general preference.
Stated the archive is pre-cutoff so this is an explicit extrapolation problem, and warned against retreating to the base rate (”the zero-skill policy”), plus a rule that no two reasoning sentences should be identical.
Closing words
In the same way as capability benchmarks moved from high school multiple-choice questions to open mathematics problems, we need to build scalable infrastructure to evaluate models’ ability to understand the specifics of human taste.
The Community Archive is a treasure trove of traces from thousands of hours of online conversation that can be used to measure model alignment with users’ deeper values and choices endorsed upon reflection.
This is something worth optimizing for; hence, it’s something worth measuring!
 | A guest post by
|