
opportunity mining | lab notes #6
mining opportunities by making substacks negotiate


This post is written primarily by Alexandre
Seb Krier recently argued that AI could solve coordination problems by “obliterating transaction costs”. Nora Ammann broke it down into solving the problems of:
Information. Finding relevant variables for the deal
Deliberation. Understanding what each participant values
Bargaining. Discovering positive-sum deals
Following up on commitments. Monitoring and enforcing the agreements.
Reducing costs 1-3 is the goal of the tool we’re building, Claude Connect, a piece of infrastructure to securely share context with friends and increase serendipity in communities.
We ran a small experiment to see what kind of opportunities can be found by LLM negotiation. For quick feedback from reality, instead of gathering substantial private data, we based it on public online writing.
We downloaded the Substack archives of 10 builders in the AI space that are openly documenting the progress on their projects, so we’d have the best chance of finding deals that are relevant to problems that matter to them.
We instructed negotiator agents to represent the interests of the authors. Their goal is to find valuable collaboration opportunities they could initiate with another party (e.g. a call, a co-written blog post, etc.).
Each negotiator is a Claude Code instance with access to the author’s writing archive. The negotiation unfolds over five sequential rounds, with both agents writing to a shared file that serves as their communication channel. The conversation is initialized with an intro prompt specifying the rules: number of rounds, example outcomes, and the option to conclude with no deal if no mutually beneficial opportunity emerges.
Deals deals deals!
Three randomly picked deal proposals (among ~ 30).
Simon Willison x Xiq
Building a Community Archive plugin for Datasette (Simon’s open source project for exploring and publishing data). Both parties would write a separate blog post, introducing each other’s project to their audience.
AI Futures delivers a 1,500–2,000-word piece on “Where Constitutional AI Frameworks Fail in Creative Contexts” by February 15, 2026, covering the surprise-as-feature problem, attribution collapse, and the training data sovereignty paradox. In return, Zvi integrates it into his constitutional AI series with co-authorship credit and promotes it via his Substack (~15K subscribers) and Twitter.
Peter Wildeford x Sara Constantin
Peter delivers a 1,000–1,500-word structured analysis on the timeline for autonomous AI-driven biological experimentation—covering bottlenecks, cross-domain comparisons, and planning implications for Sarah—by February 19, 2026. There is no immediate return obligation from Sarah, only potential future reciprocity if circumstances align.
Saying no
Around 50% of the negotiations did not conclude after the 5 rounds of discussion. The representatives were not able to find a deal that would be beneficial for both parties.
We found some of the reasoning quite subtle in how they made inferences about the value of the writer they represented. For instance, when asking to find collaboration opportunities between xiq and Alexandre, here is what Alexandre’s negotiators decided:
The negotiation concluded with no new conversation recommended beyond the existing collaboration. Alexandre’s assistant argued that forcing additional coordination would prematurely collapse Alexandre’s research portfolio when he needs space to let parallel experiments mature.
The agent was able to infer a relevant non-explicit value (diversity of research portfolio) and defend it. We were expecting LLM personalities to be too agreeable to be effective negotiators, but this experiment validated that they can say no.
a relevance bottleneck?
Though it is still probably the case that the agents should say no more of the time. Some deals look OK (e.g., xiq thought about reaching out to Simon Willison to propose a collaboration, but it feels like a stretch to start with a technical collab), many seem too high-effort for little rewards (like Peter Wilford doing a forecasting report with no immediate return).
But who are we to judge? Who knows how much Peter would value Sarah’s future reciprocity? Maybe it’s a connection he would be interested in deepening. We have no way to get to know the opportunity cost, the counterfactuals: how much does a user need opportunity? What is the bar to spend 1 hour in? That’s a problem.
Even prolific Substacks contain little information about what their writers value. Most of their pieces are stories meant to be informative or entertaining. They don’t share the specifics of the problems they are personally encountering.
Historical data is great to have a model of what they can offer, but not what they demand.
Coming back to the framework from the introduction, it seems that deliberation costs are a bottleneck over bargaining and information costs in this setup.
The email check
We tested our qualitative intuition further by having Claude Sonnet scan each archive’s 20 most recent posts for problems. To score what it found, we asked the model to estimate two things:
how excited an author would be to receive an unexpected email about the problem, and
how long after publication that email would still feel relevant to them.
To be considered a “problem”, the issue must be clearly identifiable from the text—for example, when the author explicitly describes a challenge they’re tackling or mentions they’re hiring for a role. When the LLM finds no clear problem in a post, it returns an empty string, which explains the variation in problem counts across authors.
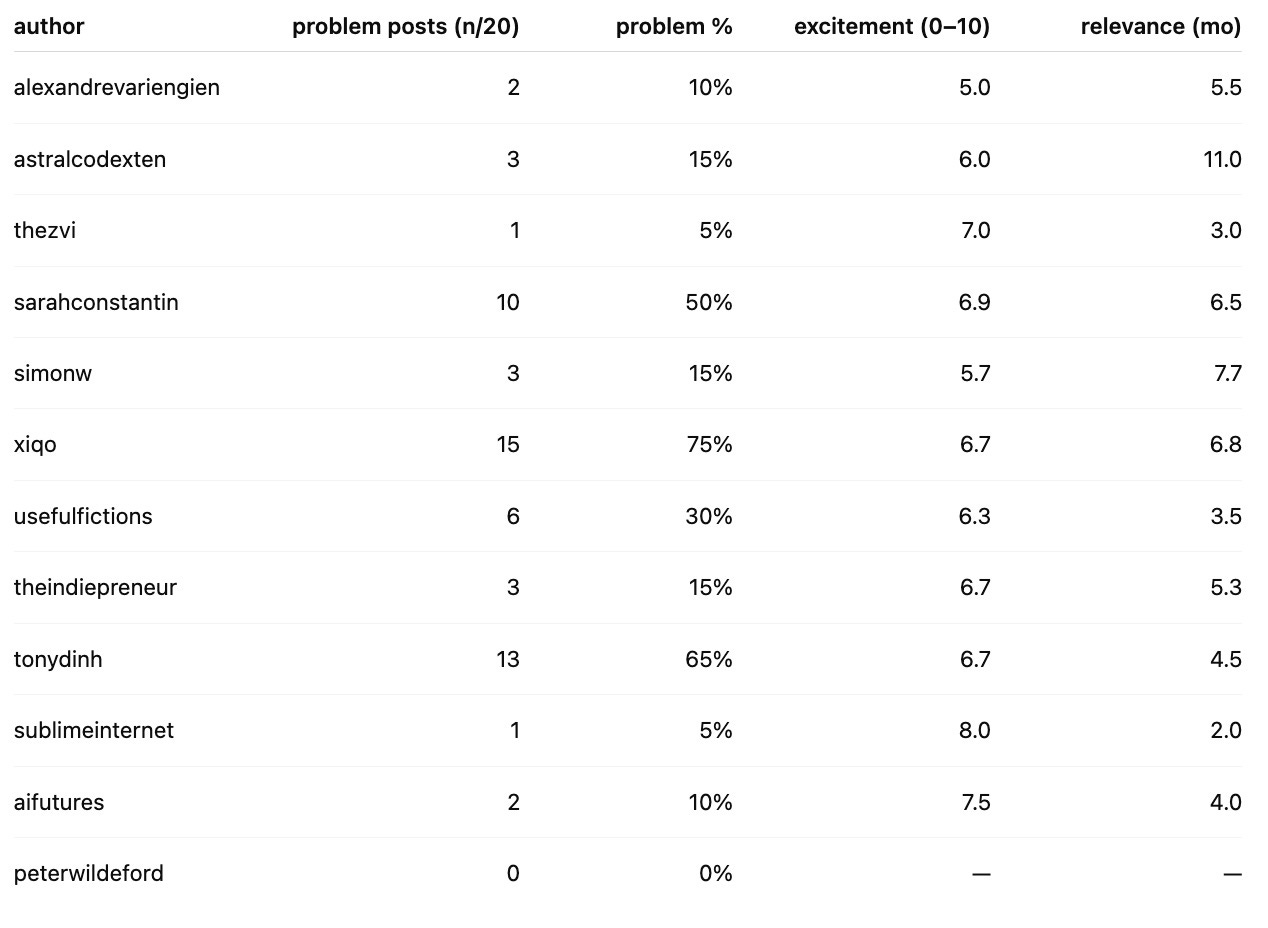
Table: Relevance is an estimate of how many months after publication a problem might stay relevant. The frequency of posting varies a lot, between 1-20 posts/mo, but we omitted that for readability.
A few patterns stand out. Authors who publish frequently in a short period tend to surface fewer total problems, suggesting a cap on how many actionable problems people share on Substack regardless of output volume.
The wide range in problem counts—from 15 for xiqo down to 0 for peterwildeford—actually increases our trust in the method: it matches each author’s style, with standalone essay writers like Zvi surfacing fewer problems than builders posting regular work updates like xiqo.
But most importantly, even in the best cases, we’re looking at roughly 1–3 problems per month. Anyone running a project has clearly more going on than that. Substack writing simply isn’t where people share most of what they need.
A porous membrane to increase your luck surface area
We need freshness! This means continuously maintaining a collection of up-to-date information about the user. What problems are they working on today? What books are they reading? What topics are top of mind for them?
These questions are close to the multi-billion dollar “which product would this user buy?” on which social media built their wealth. The difference is that, with us, users have control over their data as the files are end-to-end encrypted, and the opportunity scanning happens on the users’ node using their friend’s data.
Data is shared with friends according to a custom privacy policy that dictates what is shared with whom. We think of it as the user maintaining a porous membrane around their digital footprint.
Technically, this means solving the problems of:
Data Ingestion. Finding up-to-date information without making the user feel like a clear privacy overreach. To start, an easy option is to add public live data like Bluesky or Substack posts.
Privacy. From the data, filtering what can be shared with whom. Maintaining different access groups and giving the user control over what gets shared. The key here is to use AI to have a good default. So the user will, in 90% of the cases, hit enter to validate the pre-made choice.
Continuous opportunity scanning. The recall needs to be high; we’d rather have one great opportunity per week than 3 boring opportunities per day.
Building this porous membrane is our current focus. Stay posted for future updates!
 | A guest post by
|
This is dope and love the "proposals". I could imagine that this would be cool for companies open to external partnerships.
Amazing! I've been background thinking about similar things for some months (e.g. you can see my comments on Nora's post: https://www.lesswrong.com/posts/mtASw9zpnKz4noLFA/gradual-paths-to-collective-flourishing?commentId=ytoiDjkp7eLNjxzKH). Great to see someone prototyping!
I think the real magic here is less about 'negotiation' and more about discovery and networking (or 'mining', as you put it) - something like an aligned recommender system specialised to finding opportunities for coordination and collaboration. There's a step 0: finding potential counterparties! https://www.lesswrong.com/posts/hqdvZGhxC45g57a6s/oliver-sourbut-s-shortform?commentId=AnhGvQvtmkYhMgSMj
I expect this sort of thing fails to scale naively, but I'm also reasonably confident that a combination of 'wish indexing' with well-integrated networking agents can get *much* further in principle. We'll likely publish something on this soon as part of the 'design sketches for a more sensible world' (https://newsletter.forethought.org/p/design-sketches-for-a-more-sensible).
I'm also interested to see where this sort of thing could go for the n>2 case, which might get quite potent, a kind of evolution of change.org or kickstarter.